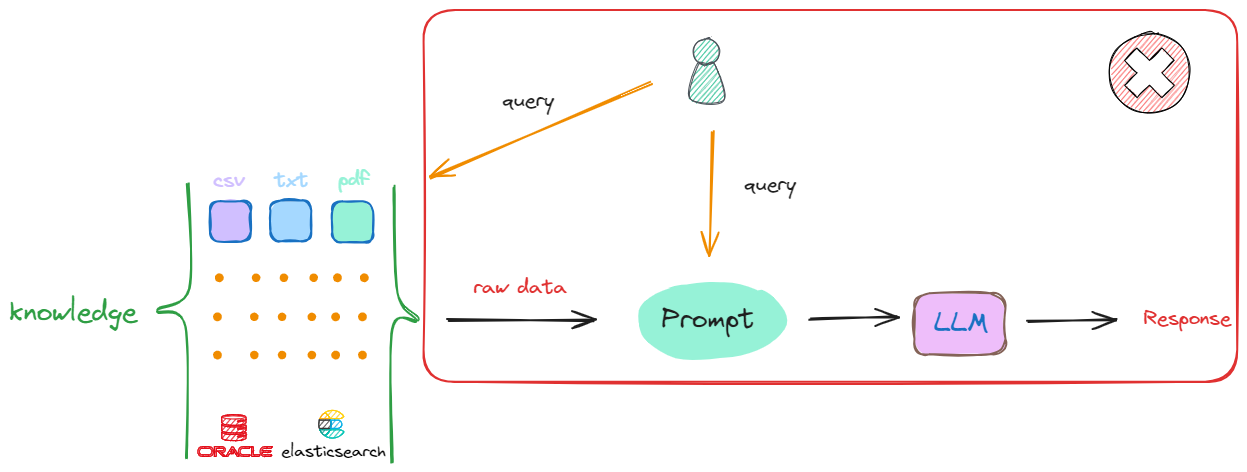
首先通过一张图来理解Langchain在模型开发中的地位。我们现在使用的各大模型,像DeepSeek、ChatGLM等,都属于LLM(Large Language Model,大语言模型)。而Langchain则是基于LLM的框架,对大语言模型的功能进行了拓展,增加了像RAG(Retrieval-Augmented Generation,检索增强生成)、MCP(Multi-Chain Processing,多链处理)等功能。这些功能通过结合外部知识库、分块处理文本、向量相似性检索等技术,显著降低了模型的幻觉(Hallucination),同时提高了生成内容的准确性与专业性。
从图中可以看到,Langchain的工作流程包括文档加载、文本分块、嵌入(Embedding)、向量存储、相似性检索等步骤,最终通过Prompt Template生成高质量的答案。这一流程使得模型能够更高效地利用结构化或非结构化数据,从而更好地满足实际应用的需求。
下面,我们来简单地基于deepseek结合Langchain进行快速的开发测试
一、各类大语言模型接入 LangChain 首先
1 2 pip install langchain
在进行 LangChain 开发之前,首先需要准备一个可以进行调用的大模型,这里我们选择使用 DeepSeek 的大模型,并使用 DeepSeek 官方的 API_KEY 进行调用。如果初次使用,需要先在 DeepSeek 的官网 DeepSeek 开放平台 上进行注册并创建一个新的 API_KEY。
注册好 DeepSeek 的 API_KEY 后,首先在项目同级目录下创建一个 .env 文件,用于存储 DeepSeek 的 API_KEY 。(务必要创建 .env 文件,用于存储 DeepSeek 的 API_KEY ,因为后续 Langchain 会使用到)
接下来通过 python-dotenv 库读取 .env 文件中的 API_KEY,使其加载到当前的运行环境中,代码如下:
1 pip install python-dotenv
1 2 3 4 5 6 import osfrom dotenv import load_dotenvTrue )"DEEPSEEK_API_KEY" )
我们在当前的运行环境下不使用 LangChain,直接使用 DeepSeek 的 API 进行网络连通性测试,测试代码如下:
先调用模型进行简单的测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from openai import OpenAIimport osfrom dotenv import load_dotenvTrue )"DEEPSEEK_API_KEY" )"https://api.deepseek.com" )"deepseek-chat" ,"role" : "system" ,"content" :"你是乐于助人的助手,请根据用户的问题给出回答" },"role" : "user" ,"content" :"你好,请你介绍一下你自己。" }print (response.choices[0 ].message.content)
可以接收到类似下面的回复:
1 2 3 4 5 6 7 8 9 10 11 12 你好!我是一个乐于助人的AI助手,随时准备为你提供各种帮助。无论是解答问题、提供建议、协助学习、处理日常事务,还是陪你聊天,我都会尽力满足你的需求。
如果可以正常收到 DeepSeek 模型的响应,则说明 DeepSeek 的 API 已经可以正常使用且网络连通性正常。
接下来我们要考虑的是,对于这样一个 DeepSeek 官方的 API ,如何接入到 LangChain 中呢?其实非常简单,我们只需要使用 LangChain 中的一个 DeepSeek 组件即可像上述代码一样,直接使用相同的 DeepSeek_API_KEY 与大模型进行交互。因此,我们首先需要安装 LangChain 的 DeepSeek 组件,安装命令如下:
1 pip install langchain-deepseek
这个库并不会被显式地调用,但是在后台运行过程中是会调用这个库的,所以务必要安装这个库
安装好LangChain集成DeepSeek模型的依赖包后,需要通过一个init_chat_model函数来初始化大模型,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue ) "deepseek-reasoner" , model_provider="deepseek" )"你好,请你介绍一下你自己。" print (result.content)
不仅仅是DeepSeek模型,LangChain还支持其他很多大模型,如OpenAI、Qwen、Gemini等,我们只需要在init_chat_model函数中指定不同的模型名称,就可以调用不同的模型。关于LangChain都支持哪些大模型以及每个模型对应的是哪个第三方依赖包,大家可以在LangChain的官方文档 中找到。
考虑到后续要实现RAG需要Embedding模型,而国内只有Dashscope的Embedding模型的api比较稳定,因此在此介绍一下如何接入Dashscope。Dashscope原名是阿里云的灵积社区,也是国内最大的API集成平台,其中包含了各类开源模型(如Qwen3系列模型)和国内在线模型(如DeepSeek、BaiChuan)模型API服务,现在已合并入阿里云百炼平台 。对于国内开发者来说,若要使用Qwen系列模型API(而非本地部署),那么Dashscope平台提供的API服务肯定是最合适的。
而百炼API获取方式也非常简单,只需注册阿里云账号,然后前往我的API页面 进行充值和注册即可:
然后即可调用海量各类模型了:
当我们完成了DashScope API注册后,即可使用如下代码进行模型调用(需要提前将DASHSCOPE_API_KEY写到本地.env文件中):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import osfrom openai import OpenAIfrom dotenv import load_dotenvTrue ) "DASHSCOPE_API_KEY" ),"https://dashscope.aliyuncs.com/compatible-mode/v1" ,"qwen-plus" ,"role" : "system" , "content" : "You are a helpful assistant." },"role" : "user" , "content" : "你是谁?" },print (completion.model_dump_json())
当然,也可以将DashScope中各类模型接入LangChain:
1 pip install --upgrade dashscope -i https://pypi.tuna.tsinghua.edu.cn/simple
1 2 3 4 5 6 7 8 9 from langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvTrue ) "你好,请你介绍一下你自己。" print (result.content)
【补充】ollama开源大模型接入LangChain
当然,除了在线大模型的接入,langChain也只是使用Ollama、vLLM等框架启动的本地大模型。这里以ollama为例进行演示。
1 pip install langchain-ollama
注意,这里要确保ollama已经顺利开启,并查看当前模型名称:
然后即可使用如下方法接入LangChain:
1 2 3 4 5 6 7 from langchain_ollama import ChatOllama"deepseek-r1" )"你好,请你介绍一下你自己。" print (result.content)
二、LangChain 核心功能 Chain 的搭建 LangChain之所以被称为LangChain,其核心概念就是Chain。 Chain翻译成中文就是“链”。一个链,指的是可以按照某一种逻辑,按顺序组合成一个流水线的方式。比如我们刚刚实现的问答流程: 用户输入一个问题 –> 发送给大模型 –> 大模型进行推理 –> 将推理结果返回给用户。这个流程就是一个链。
例如,我们这里可以先尝试着搭建一个简单的链,将模型输出结果“过滤”为一个纯字符串格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_core.output_parsers import StrOutputParserfrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"你好,请你介绍一下你自己。" print (result)
此时result就不再是包含各种模型调用信息的结果,而是纯粹的模型响应的字符串结果。而这里用到的StrOutputParser()实际上就是用于构成LangChain中一个链条的一个对象,其核心功能是用于处理模型输出结果。同时我们也能发现,只需要使用Model | OutputParser,即可高效搭建一个链。
一个最基本的Chain结构,是由Model和OutputParser两个组件构成的,其中Model是用来调用大模型的,OutputParser是用来解析大模型的响应结果的。
类似这种结果解析器还有很多,稍后我们会继续进行介绍。
接下来我们尝试为当前的执行流程添加一个提示词模板,我们可以借助ChatPromptTemplate非常便捷的将一个提示词模板同样以链的形式加入到当前任务中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_core.output_parsers import StrOutputParserfrom langchain.chat_models import init_chat_modelfrom langchain.prompts import ChatPromptTemplatefrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"system" , "你是一个乐意助人的助手,请根据用户的问题给出回答" ),"user" , "这是用户的问题: {topic}, 请用 yes 或 no 来回答" )"请问 1 + 1 是否 大于 2?" "topic" : question})print (result)
至此,我们就搭建了一个非常基础的链。在LangChain中,一个基础的链主要由三部分构成,分别是提示词模板、大模型和结果解析器(结构化解析器):
1 2 3 4 5 6 用户输入
结构化解析器功能最多,一些核心的结构化解析器功能如下:
解析器名称
功能描述
类型
BooleanOutputParser 将LLM输出解析为布尔值
基础类型解析
DatetimeOutputParser 将LLM输出解析为日期时间
基础类型解析
EnumOutputParser 解析输出为预定义枚举值之一
基础类型解析
RegexParser 使用正则表达式解析LLM输出
模式匹配解析
RegexDictParser 使用正则表达式将输出解析为字典
模式匹配解析
StructuredOutputParser 将LLM输出解析为结构化格式
结构化解析
YamlOutputParser 使用Pydantic模型解析YAML输出
结构化解析
PandasDataFrameOutputParser 使用Pandas DataFrame格式解析输出
数据处理解析
CombiningOutputParser 将多个输出解析器组合为一个
组合解析器
OutputFixingParser 包装解析器并尝试修复解析错误
错误处理解析
RetryOutputParser 包装解析器并尝试修复解析错误
错误处理解析
RetryWithErrorOutputParser 包装解析器并尝试修复解析错误
错误处理解析
ResponseSchema 结构化输出解析器的响应模式
辅助类
一些功能实现如下
例如借助结构化解析器可以将yes or no转化为True or Fasle:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain.output_parsers import BooleanOutputParserfrom langchain.chat_models import init_chat_modelfrom langchain.prompts import ChatPromptTemplatefrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"system" , "你是一个乐意助人的助手,请根据用户的问题给出回答" ),"user" , "这是用户的问题: {topic}, 请用 yes 或 no 来回答" )"请问 1 + 1 是否 大于 2?" print (result)
而StructuredOutputParser则可以在文档中提取指定的结构化信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from langchain.chat_models import init_chat_modelfrom langchain_core.prompts import PromptTemplatefrom langchain.output_parsers import ResponseSchema, StructuredOutputParserfrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"name" , description="用户的姓名" ),"age" , description="用户的年龄" )"请根据以下内容提取用户信息,并返回 JSON 格式:\n{input}\n\n{format_instructions}" "input" : "用户叫李雷,今年25岁,是一名工程师。" })print (result)
这里我们在 PromptTemplate 中,定义了两个占位符变量:
而格式化说明使用format_instructions进行标识其实也是一种约定俗称的方法,上述代码也就是相当于在创建Chain的时候,我们就输入了{format_instructions}对应的字符串parser.get_format_instructions(),我们也可以通过如下代码进行打印查看:
1 print (parser.get_format_instructions())
输出为:
1 2 3 4 5 6 7 8 The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
我们也可以进一步创建复合链
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from langchain.chat_models import init_chat_modelfrom langchain_core.prompts import PromptTemplatefrom langchain.output_parsers import ResponseSchema, StructuredOutputParserfrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"请根据以下新闻标题撰写一段简短的新闻内容(100字以内):\n\n标题:{title}" "time" , description="事件发生的时间" ),"location" , description="事件发生的地点" ),"event" , description="发生的具体事件" ),"请从下面这段新闻内容中提取关键信息,并返回结构化JSON格式:\n\n{news}\n\n{format_instructions}" "title" : "苹果公司在加州发布新款AI芯片" })print (result)
管道操作符 | 会自动将前一个链的输出作为后一个链的输入 ,整体流程如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 用户输入(title) _ gen_ prompt │ _ pro │
也可以借助LangChain适配器设置自定义可运行的节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from langchain.chat_models import init_chat_modelfrom langchain_core.prompts import PromptTemplatefrom langchain.output_parsers import ResponseSchema, StructuredOutputParserfrom langchain_core.runnables import RunnableLambdafrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"请根据以下新闻标题撰写一段简短的新闻内容(100字以内):\n\n标题:{title}" "time" , description="事件发生的时间" ),"location" , description="事件发生的地点" ),"event" , description="发生的具体事件" ),"请从下面这段新闻内容中提取关键信息,并返回结构化JSON格式:\n\n{news}\n\n{format_instructions}" def debug_print (x ):print ("中间结果(新闻正文):" , x)return x"title" : "苹果公司在加州发布新款AI芯片" })print (result)
通过上述不同的尝试,我们就已经理解了在langChain中,如何使用ChatPromptTemplate、Model、OutputParser来构建一个简单的Chain。其中:
ChatPromptTemplate 是用来构建提示模板的,将输入的问题转化为消息列表,可以设置系统指令,也可以添加一些变量;Model 是用来调用大模型的,可以指定使用不同的模型;OutputParser 是用来解析大模型的响应结果的,可以指定使用不同的解析器。
[补充] LCEL关键概念介绍
什么是 LCEL?——LangChain Expression Language 详解
在现代大语言模型(LLM)应用的构建中,LangChain 提供了一种全新的表达范式,被称为 LCEL(LangChain Expression Language)
一、LCEL 的定义
LCEL,全称为 **LangChain Expression Language**,是一种专为 LangChain 框架设计的表达语言。它通过一种链式组合的方式,允许开发者使用清晰、声明式的语法来构建语言模型驱动的应用流程。
简单来说,LCEL 是一种“函数式管道风格”的组件组合机制,用于连接各种可执行单元(Runnable)。这些单元包括提示模板、语言模型、输出解析器、工具函数等。
二、设计目的
LCEL 的设计初衷在于:
模块化构建 :将模型调用流程拆解为独立、可重用的组件。逻辑可视化 :通过语法符号(如管道符 |)呈现出明确的数据流路径。统一运行接口 :所有 LCEL 组件都实现了 .invoke()、.stream()、.batch() 等标准方法,便于在同步、异步或批处理环境下调用。脱离框架限制 :相比传统的 Chain 类和 Agent 架构,LCEL 更轻量、更具表达力,减少依赖的“黑盒”逻辑。
三、核心组成
Runnable 接口
LCEL 的一切基础单元都是 Runnable 对象,它是一种统一的可调用接口,支持如下形式:
.invoke(input):同步调用.stream(input):流式生成.batch(inputs):批量执行
管道运算符 |
这是 LCEL 最具特色的语法符号。多个 Runnable 对象可以通过 | 串联起来,形成清晰的数据处理链。例如:
表示数据将依次传入提示模板、模型和输出解析器,最终输出结构化结果。
PromptTemplate 与 OutputParser
LCEL 强调组件之间的职责明确,Prompt 只负责模板化输入,Parser 只负责格式化输出,Model 只负责推理。
四、典型优势
特性
描述
简洁语法
使用 `
` 运算符提升可读性
灵活组合
可任意组合 Prompt、模型、工具、函数等组件
明确边界
每个步骤职责分明,方便调试与重用
可嵌套扩展
支持函数包装、自定义中间组件和流式拓展
与 Gradio/FastAPI 集成良好
可用于构建 API、UI 聊天等多种场景
五、总结
LCEL 是 LangChain 在 2024 年末引入的一项重要特性,标志着从传统 Agent 架构向“声明式、组合式”开发范式的转变。它不仅让开发者能以更清晰的方式组织 LLM 工作流,也大大提高了系统的可维护性与可测试性。
三、LangChain 记忆存储与搭建多轮对话机器人 在langChain中构建一个基本的问答机器人仅需要使用一个Chain便可以快速实现,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_core.output_parsers import StrOutputParserfrom langchain.prompts import ChatPromptTemplatefrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue ) "system" , "你叫小橘,是一名乐于助人的助手。" ),"user" , "{input}" )"deepseek-chat" , model_provider="deepseek" )"你好,请你介绍一下你自己。" print (result)
在LangChain中,我们可以通过人工拼接消息队列,来为每次模型调用设置多轮对话记忆。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from langchain_core.messages import AIMessage, HumanMessage, SystemMessagefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain.chat_models import init_chat_modelfrom langchain_core.output_parsers import StrOutputParserfrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"你叫小橘,是一名乐于助人的助手。" ),"messages" ),print ("🔹 输入 exit 结束对话" )while True :input ("你:" )if user_query.lower() in {"exit" , "quit" }:break "messages" : messages_list})print ("小橘:" , assistant_reply)50 :]
此外还有一个问题是,大家经常看到的问答机器人其实都是采用流式传输模式。用户输入问题,等待模型直接返回回答,然后用户再输入问题,模型再返回回答,这样循环下去,用户输入问题和模型返回回答之间的时间间隔太长,导致用户感觉机器人反应很慢。所以LangChain提供了一个astream方法,可以实现流式输出,即一旦模型有输出,就立即返回,这样用户就可以看到模型正在思考,而不是等待模型思考完再返回。
实现的方法也非常简单,只需要在调用模型时将invoke方法替换为astream方法,然后使用async for循环来持续获取模型的输出即可。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_core.output_parsers import StrOutputParserfrom langchain.chat_models import init_chat_modelfrom langchain.prompts import ChatPromptTemplatefrom dotenv import load_dotenvimport asyncioTrue ) "system" , "你叫小智,是一名乐于助人的助手。" ),"user" , "{input}" )"deepseek-chat" , model_provider="deepseek" )async def main ():async for chunk in qa_chain_with_system.astream({"input" : "你好,请你介绍一下你自己" }):print (chunk, end="" , flush=True )
同样的,可以进一步为每次模型调用设置多轮对话记忆。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import asynciofrom langchain_core.messages import AIMessage, HumanMessage, SystemMessagefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain.chat_models import init_chat_modelfrom langchain_core.output_parsers import StrOutputParserfrom dotenv import load_dotenvTrue ) "deepseek-chat" , model_provider="deepseek" )"你叫小橘,是一名乐于助人的助手。" ),"messages" ),async def main ():print ("🔹 输入 exit 结束对话" )while True :input ("你:" )if user_query.lower() in {"exit" , "quit" }:break print ("小橘:" , end="" , flush=True )"" async for chunk in chain.astream({"messages" : messages_list}):print (chunk, end="" , flush=True )print () 50 :]
如上所示展示的问答效果就是我们在构建大模型应用时需要实现的流式输出效果。接下来我们就进一步地,使用gradio来开发一个支持在网页上进行交互的问答机器人。Gradio 是一个用于快速构建机器学习模型交互式演示界面 的 Python 库。它允许开发者用几行代码创建 Web 应用,无需前端知识即可让用户通过浏览器输入数据并查看模型预测结果。
首先需要安装一下gradio的第三方依赖包
完整实现的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import gradio as gr from langchain.chat_models import init_chat_model from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.messages import SystemMessage, HumanMessage, AIMessage from dotenv import load_dotenv True ) "deepseek-chat" , model_provider="deepseek" )"你叫小橘,是一名乐于助人的助手。" ), "messages" ), """ .main-container {max-width: 1200px; margin: 0 auto; padding: 20px;} # 主容器样式 .header-text {text-align: center; margin-bottom: 20px;} # 标题样式 """ def create_chatbot () -> gr.Blocks:with gr.Blocks(title="DeepSeek Chat" , css=CSS) as demo: with gr.Column(elem_classes=["main-container" ]):"# 流式对话机器人" , elem_classes=["header-text" ])500 , True , "https://smallgoodgood.top/images/23.jpg" , "https://smallgoodgood.top/images/23.jpg" , "请输入您的问题..." , container=False , scale=7 ) "发送" , scale=1 , variant="primary" ) "清空" , scale=1 ) async def respond (user_msg: str , chat_hist: list , messages_list: list ):""" 处理用户输入并生成AI回复(流式) 参数: user_msg: 用户输入的消息 chat_hist: 聊天历史(用于显示在界面上) messages_list: 保存的Message对象列表(用于模型处理) 返回: 更新后的msg, chat_hist和messages_list """ if not user_msg.strip():yield "" , chat_hist, messages_list return None )]yield "" , chat_hist, messages_list "" async for chunk in qa_chain.astream({"messages" : messages_list}):1 ] = (user_msg, partial)yield "" , chat_hist, messages_list 50 :] yield "" , chat_hist, messages_listdef clear_history ():"""清空聊天历史""" return [], "" , [] return demo "127.0.0.1" , server_port=7860 , share=False , debug=True )
运行后,在浏览器访问http://127.0.0.1:7860即可进行问答交互。
当然这只是最简单的问答机器人实现形式,实际上企业应用的问答机器人往往需要更加复杂的逻辑,比如用户权限管理、上下文记忆等
四、LangChain 接入工具流程 在LangChain生态中,既有海量丰富的内置工具 ,同时也能接入自定义工具,不仅能通过搭建一个个链(Chain)将工具封装在对应的工作流中,也能借助LangChain Agent功能,实时灵活创建不同的Chain来完成复杂工具调用,甚至还可以使用更高级的LangGraph进行工作流编排。
本小节我们将首先介绍如何在LangChain中接入外部工具,然后从下一小节开始,我们会进一步介绍如何使用LangChain Agent库来搭建更加复杂的工作流。
这里我们首先介绍最基本的LangChain接入工具流程。在MCP爆火之前,LangChian生态中就已经内置集成了非常多的实用工具,开发者可以快速调用这些工具完成更加复杂工作流的开发。
LangChain内置工具列表
我们就以其中代码解释器为例,来介绍如何将内置工具 接入LangChain的工作流中。
1 pip install -qU langchain-community langchain-experimental pandas
Telco数据集是Kaggle分享的一个高分数据集,是Kaggle平台上非常经典的围绕偏态数据集建模的数据集。该数据源自IBM商业社区(IBM Business Analytics Community )上分享的数据集,用于社区成员内部学习使用。
根据IBM商业社区分享团队描述,该数据集为某电信公司在加利福尼亚为7000余位用户(个人/家庭)提供电话和互联网服务的相关记录。由于该数据集并不是竞赛数据集,因此数据集的下载方式相对容易,官网也提供了网页下载选项。我们可以在该数据集的Kaggle主页 看到数据集的相关信息以及下载地址。当然,熟练使用Kaggle主页获取数据和挖掘信息(而不是借助第三方渠道),也是算法工程师必备技能之一。
我们可以先用以下代码查看数据集的一些基本信息:
1 2 3 4 5 import pandas as pd'WA_Fn-UseC_-Telco-Customer-Churn.csv' )'max_colwidth' ,200 )print (dataset.head(5 ))
其中数据集各字段解释如下:
字段
解释
customerID
用户ID
gender
性别
SeniorCitizen
是否是老年人(1代表是)
Partner
是否有配偶(Yes or No)
Dependents
是否经济独立(Yes or No)
tenure
用户入网时间
PhoneService
是否开通电话业务(Yes or No)
MultipleLines
是否开通多条电话业务(Yes 、 No or No phoneservice)
InternetService
是否开通互联网服务(No、DSL数字网络或filber potic光线网络)
OnlineSecurity
是否开通网络安全服务(Yes、No or No internetservice)
OnlineBackup
是否开通在线备份服务(Yes、No or No internetservice)
DeviceProtection
是否开通设备保护服务(Yes、No or No internetservice)
TechSupport
是否开通技术支持业务(Yes、No or No internetservice)
StreamingTV
是否开通网络电视(Yes、No or No internetservice)
StreamingMovies
是否开通网络电影(Yes、No or No internetservice)
Contract
合同签订方式(按月、按年或者两年)
PaperlessBilling
是否开通电子账单(Yes or No)
PaymentMethod
付款方式(bank transfer、credit card、electronic check、mailed check)
MonthlyCharges
月度费用
TotalCharges
总费用
Churn
是否流失(Yes or No)
接下来测试LangChain内置代码解释器工具功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import pandas as pd from langchain_experimental.tools import PythonAstREPLTool 'WA_Fn-UseC_-Telco-Customer-Churn.csv' )locals ={"df" : df})print (tool.invoke("df['SeniorCitizen'].mean()" )) print (df['MonthlyCharges' ].mean())
PythonAstREPLTool是一个代码执行工具,特点:
安全地在沙箱中执行Python代码
可以限制可访问的变量和函数
常用于AI代理(Agent)中让AI动态执行代码
通过locals参数,我们只暴露df变量给工具
然后invoke()方法执行代码字符串并返回结果
接下来创建LangChain工作流并绑定内置工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pandas as pd from langchain_experimental.tools import PythonAstREPLTool from langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )"deepseek-chat" , model_provider="deepseek" )'WA_Fn-UseC_-Telco-Customer-Churn.csv' )locals ={"df" : df})"我有一张表,名为'df',请帮我计算MonthlyCharges字段的均值。" print (response)
通过观察输出,此时我们发现,LangChain回复的结果就不再是简单的文字内容,而是一条调用外部工具的消息。我们可以使用如下方法将这条消息里面涉及到代码运行的核心参数提取出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import pandas as pd from langchain_experimental.tools import PythonAstREPLTool from langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParserfrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )"deepseek-chat" , model_provider="deepseek" )'WA_Fn-UseC_-Telco-Customer-Churn.csv' )locals ={"df" : df})True )"我有一张表,名为'df',请帮我计算MonthlyCharges字段的均值。" print (response)
此时输出:
1 {'query': "df['MonthlyCharges'].mean()"}
接着通过设置提示词模板,再在当前链中加入一个tool外部函数的环节,即可让大模型输出的参数直接带入到tool中进行运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import pandas as pd from langchain_core.prompts import ChatPromptTemplatefrom langchain_experimental.tools import PythonAstREPLTool from langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParserfrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )f""" 你可以访问一个名为 `df` 的 pandas 数据框,你可以使用df.head().to_markdown() 查看数据集的基本信息, \ 请根据用户提出的问题,编写 Python 代码来回答。只返回代码,不返回其他内容。只允许使用 pandas 和内置库。 """ "system" , system),"user" , "{question}" )"deepseek-chat" , model_provider="deepseek" )'WA_Fn-UseC_-Telco-Customer-Churn.csv' )locals ={"df" : df})True )print (chain.invoke({"question" : "请帮我计算MonthlyCharges字段的均值。" }))
同时,按照此前介绍的,我们还可以在链条中加入一个打印的环节,让模型将编写的Python代码进行打印:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import pandas as pd from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain_experimental.tools import PythonAstREPLTool from langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParserfrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )f""" 你可以访问一个名为 `df` 的 pandas 数据框,你可以使用df.head().to_markdown() 查看数据集的基本信息, \ 请根据用户提出的问题,编写 Python 代码来回答。只返回代码,不返回其他内容。只允许使用 pandas 和内置库。 """ "system" , system),"user" , "{question}" )"deepseek-chat" , model_provider="deepseek" )'WA_Fn-UseC_-Telco-Customer-Churn.csv' )locals ={"df" : df})True )def code_print (res ):print ("即将运行Python代码:" , res['query' ])return resprint (chain.invoke({"question" : "请帮我分析gender、SeniorCitizen和Churn三个字段之间的相关关系。" }))
至此,一个简单的包含官方内置工具 的代码解释器工作流就搭建完成了。
接下来是LangChain接入自定义外部工作流程
这里我们以实时获取天气数据为例,尝试创建一个外部函数,并将其封装为LangChian的一项基础工作。在langChain中,如果想要把一个普通的函数,变成一个可以被大模型调用的工具,只需要将函数包装成一个Tool对象即可。
这里我们首先需要获取OpenWeather API Key,并写入.env文件中,方便后续进行天气查询
浏览器访问openweathermap官方网站
接着注册并绑定邮箱
最后进入openweathermap官方网站OpenWeather API Key
然后先尝试创建这个外部函数进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import osimport requests,jsonfrom dotenv import load_dotenvTrue )"OPENWEATHER_API_KEY" )print ("Loaded API Key:" , OPENWEATHER_API_KEY) def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)print (get_weather("Beijing" ))
注意:如果返回401,请不要惊慌,因为API Key会过一会儿生效,时间一般在一小时内
紧接着将其封装为LangChain能够识别的外部函数,并且如果想让大模型调用某一个外部工具,需要使用bind_tools方法,将工具绑定到模型上。接下来,便可以通过新的llm_with_tools模型通过invoke方法来调用模型。这会产生一个包含tool_calls 的模型响应。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import osimport requests,jsonfrom langchain.chat_models import init_chat_modelfrom langchain_core.tools import toolfrom dotenv import load_dotenvTrue )"deepseek-chat" , model_provider="deepseek" )"OPENWEATHER_API_KEY" )print ("Loaded API Key:" , OPENWEATHER_API_KEY) @tool def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)print (get_weather.name)print (get_weather.description)print (get_weather.args)"你好, 请问北京的天气怎么样?" )print (response)print (response.additional_kwargs)
我们继续调用JsonOutputKeyToolsParser输出解析器来处理模型响应。并加入一个tool外部函数的环节,即可让大模型输出的参数直接带入到tool中进行运行,就能顺利的将用户的需求转化为天气查询,并完成外部工具完成自动运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import osimport requests,jsonfrom langchain.chat_models import init_chat_modelfrom langchain_core.tools import toolfrom langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParserfrom dotenv import load_dotenvTrue )"deepseek-chat" , model_provider="deepseek" )"OPENWEATHER_API_KEY" )print ("Loaded API Key:" , OPENWEATHER_API_KEY) @tool def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)print (get_weather.name)print (get_weather.description)print (get_weather.args)True )"你好, 请问北京的天气怎么样?" )print (response)
能够看到,此时Chain就能顺利的将用户的需求转化为天气查询,并完成外部工具的自动运行。但只有这一步还不够,我们还需要将调用工具返回的结果转化为一个模型的问答:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import osimport requests,jsonfrom langchain.chat_models import init_chat_modelfrom langchain_core.tools import toolfrom langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParserfrom langchain.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom dotenv import load_dotenvTrue )"deepseek-chat" , model_provider="deepseek" )"OPENWEATHER_API_KEY" )print ("Loaded API Key:" , OPENWEATHER_API_KEY) @tool def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)print (get_weather.name)print (get_weather.description)print (get_weather.args)True )"""你将收到一段 JSON 格式的天气数据,请用简洁自然的方式将其转述给用户。 以下是天气 JSON 数据: ```json {weather_json} ``` 请将其转换为中文天气描述,例如: “北京当前天气晴,气温为 23°C,湿度 58%,风速 2.1 米/秒。” 只返回一句话描述,不要其他说明或解释。""" "请问北京今天的天气如何?" )print (response)
最终,我们将这两个Chain进行拼接,即构成完整的外部工具调用流程。
接着,我们来了解一下LangChain接入自定义外部工作流程
首先要了解一下 Function calling 基本原理
我们都知道,能调用外部工具,是大模型进化为智能体Agent的关键,如果不能使用外部工具,大模型就只能是个简单的聊天机器人,甚至连查询天气都做不到。由于底层技术限制啊,大模型本身是无法和外部工具直接通信的,因此Function calling的思路,就是创建一个外部函数(function)作为中介,一边传递大模型的请求,另一边调用外部工具,最终让大模型能够间接的调用外部工具。
例如,当我们要查询当前天气时,让大模型调用外部工具的function calling的过程就如图所示:
而完整的一次Function calling执行流程如下:
DeepSeek function calling 的三种响应模式:
在实际使用中,我们其实可以直接使用create_tool_calling_agent来快速构建工具调用代理。并使用AgentExecutor来执行代理,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import jsonimport osimport requestsfrom langchain.agents import create_tool_calling_agent, tool, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )"OPENWEATHER_API_KEY" )"deepseek-chat" , model_provider="deepseek" )@tool def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)"system" , "你是天气助手,请根据用户的问题,给出相应的天气信息" ),"human" , "{input}" ),"placeholder" , "{agent_scratchpad}" ),True )"input" : "请问今天北京的天气怎么样?" })print (response)print (response["output" ])
LangChain 中Agents模块的整体架构设计。如下所示:
在Agents的内部结构。每个Agent组件一般会由语言模型 + 提示 + 输出解析器构成,它会作为Agents的大脑去处理用户的输入。Agent能够处理的输入主要来源于三个方面:input代表用户的原始输入,Model Response指的是模型对某一个子任务的响应输出,而History则能携带上下文的信息。其输出部分,则链接到实际的工具库,需要调用哪些工具,将由经过Agent模块后拆分的子任务来决定。
而我们知道,大模型调用外部函数会分为两个过程:识别工具和实际执行。在 Message -> Agent -> Toolkits 这个流程中,负责的是将子任务拆解,然后根据这些子任务在工具库中找到相应的工具,提取工具名称及所需参数,这个过程可以视作一种“静态”的执行流程。而将这些决策转化为实际行动的工作,则会交给AgentExecutor。
所以综上需要理解的是:在LangChain的Agents实际架构中,Agent的角色是接收输入并决定采取的操作,但它本身并不直接执行这些操作。这一任务是由AgentExecutor来完成的。将Agent(决策大脑)与AgentExecutor(执行操作的Runtime)结合使用,才构成了完整的Agents(智能体),其中AgentExecutor负责调用代理并执行指定的工具,以此来实现整个智能体的功能。
这也就是为什么create_tool_calling_agent需要通过AgentExecutor才能够实际运行的原因。当然,在这种模式下,**AgentExecutor的内部已经自动处理好了关于我们工具调用的所有逻辑,其中包含串行和并行工具调用的两种常用模式。**
在大模型中,并行工具调用指的是在大模型调用外部工具时,可以在单次交互过程中可以同时调用多个工具,并行执行以解决用户的问题。如下图所示:
而在create_tool_calling_agent中,已经自动处理了并行工具调用的处理逻辑,并不需要我们在手动处理,比如接下来测试一些复杂的问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import jsonimport osimport requestsfrom langchain.agents import create_tool_calling_agent, tool, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )"OPENWEATHER_API_KEY" )"deepseek-chat" , model_provider="deepseek" )@tool def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)"system" , "你是天气助手,请根据用户的问题,给出相应的天气信息" ),"human" , "{input}" ),"placeholder" , "{agent_scratchpad}" ),True )"input" : "请问今天北京和杭州的天气怎么样,哪个城市更热?" })print (response["output" ])
从这个过程中可以明显的看出,一次性发起了同一个外部函数的两次调用请求,并依次获得了北京和杭州两个城市的天气。这就是一次标准的parallel_function_call。
接下来继续尝试进行多工具串联调用测试:
此时我们再定义一个write_file函数,用于将“文本写入本地”,然后在tools列表中直接添加write_file工具,并修改提示模版,添加write_file工具的使用场景。代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import jsonimport osimport requestsfrom langchain.agents import create_tool_calling_agent, tool, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )"OPENWEATHER_API_KEY" )"deepseek-chat" , model_provider="deepseek" )@tool def get_weather (loc ):""" 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing'; :return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ "https://api.openweathermap.org/data/2.5/weather" "q" : loc,"appid" : os.getenv("OPENWEATHER_API_KEY" ), "units" : "metric" , "lang" : "zh_cn" return json.dumps(data)@tool def write_file (content ):""" 将指定内容写入本地文件。 :param content: 必要参数,字符串类型,用于表示需要写入文档的具体内容。 :return:是否成功写入 """ return "已成功写入本地文件。" "system" , "你是天气助手,请根据用户的问题,给出相应的天气信息,如果用户需要将查询结果写入文件,请使用write_file工具" ),"human" , "{input}" ),"placeholder" , "{agent_scratchpad}" ),True )"input" : "查一下北京和杭州现在的温度,并将结果写入本地的文件中。" })print (response["output" ])
通过中间过程信息的打印,我们能够看到在一次交互过程中依次调用的get_weather查询到北京和杭州的天气,然后又将结果写入到本地的文件中。这就是一个非常典型的串行工具调用的流程,如下图所示:
五、LangChain Agent进阶功能介绍 借助LangChain Agent+内置工具快速搭建智能体
既然LangChain Agent能更加灵活调用外部工具,LangChain Agent+LangChain内置工具也能更加快速的完成复杂Agent开发。
LangChain 第三方工具集成
下面选择以LangChain 的 Tavily Search 工具
可以通过访问此站点 创建一个帐户来获取LangChain 的 Tavily Search 工具的 API 密钥,并将其加到.env文件中
langchain-tavily集成存在于包中
1 pip install -U langchain-tavily
先编写一个简单的程序验证该工具能正常运行
1 2 3 4 5 6 7 8 9 10 11 import osfrom langchain_tavily import TavilySearchfrom dotenv import load_dotenvTrue )2 )"苹果2025WWDC发布会" )print (result)
再使用LangChain Agent配合LangChain内置的Tavily Search工具快速地完成复杂Agent开发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import osfrom langchain_tavily import TavilySearchfrom langchain.agents import AgentExecutor, create_tool_calling_agent, toolfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.chat_models import init_chat_modelfrom dotenv import load_dotenvTrue )2 )"system" , "你是一名助人为乐的助手,并且可以调用工具进行网络搜索,获取实时信息。" ),"human" , "{input}" ),"placeholder" , "{agent_scratchpad}" ),"deepseek-chat" , model_provider="deepseek" )True )"input" : "请问苹果2025WWDC发布会召开的时间是?" })print (result['output' ])
接着我们来完成多智能体协作实现浏览器自动化
正如上述我们使用的create_tool_calling_agent方法,它其实在langChain中是一个通用的用来构建工具代理的方法,除此以外,langChain还封装了非常多种不同的Agent实现形式
下面是推荐的Agent创建函数:
函数名
功能描述
适用场景
create_tool_calling_agent 创建使用工具的Agent
通用工具调用
create_openai_tools_agent 创建OpenAI工具Agent
OpenAI模型专用
create_openai_functions_agent 创建OpenAI函数Agent
OpenAI函数调用
create_react_agent 创建ReAct推理Agent
推理+行动模式
create_structured_chat_agent 创建结构化聊天Agent
多输入工具支持
create_conversational_retrieval_agent 创建对话检索Agent
检索增强对话
create_json_chat_agent 创建JSON聊天Agent
JSON格式交互
create_xml_agent 创建XML格式Agent
XML逻辑格式
create_self_ask_with_search_agent 创建自问自答搜索Agent
自主搜索推理
其中比较通用场景的就是我们刚刚使用的create_tool_calling_agent,而对于一些符合OpenAI API RESTFUL API的模型,则同样可以使用create_openai_tools_agent,另外像create_react_agent可以用于一些推理任务,create_conversational_retrieval_agent则可以用于一些对话系统,具体还是需要根据实际需求来选择。
目前来说,在大模型应用开发领域有非常多的需求场景,其中一个比较热门的就是浏览器自动化,通过自动化提取网页内容,然后进行分析,最后生成报告。这样的流程提升效率和收集信息的有效途径。因此接下来,我们就尝试使用尝试使用create_openai_tools_agent来实际开发一个浏览器自动化代理。
首先,执行浏览器自动化代理需要安装一系列的第三方依赖包,如下所示:
1 pip install playwright lxml langchain_community beautifulsoup4 reportlab
此外,还需要安装 Playwright 浏览器,需要在当前虚拟环境中执行如下命令:
这个安装过程它会下载并安装 Playwright 支持的浏览器内核(注意:这里不是用我们本机已有的浏览器),包括Chromium(类似 Chrome)、Firefox、WebKit(类似 Safari),并将这些浏览器下载到本地的 .cache/ms-playwright 目录或项目的 ~/.playwright 目录中,以便 Playwright 使用稳定一致的运行环境。
这个案例的核心代码首先是需要用代理工具初始化同步 Playwright 浏览器:
1 2 3 4 5 sync_browser = create_sync_playwright_browser()
然后再通过create_openai_tools_agent接收初始化的大模型和Playwright工具构建共同构建OpenAI Tools 代理,最后通过AgentExecutor执行代理。
1 2 3 4 5 True )
完整的代码因为langChian的模块化封装非常简洁,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from langchain_community.agent_toolkits import PlayWrightBrowserToolkitfrom langchain_community.tools.playwright.utils import create_sync_playwright_browserfrom langchain import hubfrom langchain.agents import AgentExecutor, create_openai_tools_agentfrom langchain.chat_models import init_chat_modelimport osfrom dotenv import load_dotenvTrue )"DEEPSEEK_API_KEY" )"hwchase17/openai-tools-agent" )"deepseek-chat" , model_provider="deepseek" )True )if __name__ == "__main__" :"input" : "访问这个网站 https://blogroll.naosi.org/ 并用中文帮我总结一下这个网站的内容" print (response['output' ])
更进一步地,我们还可以将Playwright Agent封装成工具函数,并结合LangChain的LCEL串行链,实现一个更加复杂的浏览器自动化代理。这里定义的工具如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 @tool def summarize_website (url: str ) -> str :"""访问指定网站并返回内容总结""" try :"deepseek-chat" , model_provider="deepseek" )"hwchase17/openai-tools-agent" )False )"input" : f"访问这个网站 {url} 并帮我详细总结一下这个网站的内容,包括主要功能、特点和使用方法" return result.get("output" , "无法获取网站内容总结" )except Exception as e:return f"网站访问失败: {str (e)} " @tool def generate_pdf (content: str ) -> str :"""将文本内容生成为PDF文件""" try :"%Y%m%d_%H%M%S" )f"website_summary_{timestamp} .pdf" try :"C:/Windows/Fonts/simhei.ttf" , "C:/Windows/Fonts/simsun.ttc" , "C:/Windows/Fonts/msyh.ttc" , False for font_path in font_paths:if os.path.exists(font_path):try :'ChineseFont' , font_path))True print (f"✅ 成功注册中文字体: {font_path} " )break except :continue if not chinese_font_registered:print ("⚠️ 未找到中文字体,使用默认字体" )except Exception as e:print (f"⚠️ 字体注册失败: {e} " )'CustomTitle' ,'Heading1' ],18 ,30 ,'ChineseFont' if 'chinese_font_registered' in locals () and chinese_font_registered else 'Helvetica-Bold' 'CustomContent' ,'Normal' ],11 ,20 ,20 ,12 ,'ChineseFont' if 'chinese_font_registered' in locals () and chinese_font_registered else 'Helvetica' "网站内容总结报告" , title_style))1 , 20 ))f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} " 'Normal' ]))1 , 20 ))"=" * 50 , styles['Normal' ]))1 , 15 ))if content:'\r\n' , '\n' ).replace('\r' , '\n' )'\n' )for para in paragraphs:if para.strip():'<' , '<' ).replace('>' , '>' ).replace('&' , '&' )try :1 , 8 ))except Exception as para_error:try :'Fallback' ,'Normal' ],10 ,20 ,20 ,10 1 , 8 ))except :print (f"⚠️ 段落处理失败: {clean_para[:50 ]} ..." )continue else :"暂无内容" , content_style))1 , 30 ))"=" * 50 , styles['Normal' ]))"本报告由 Playwright PDF Agent 自动生成" , styles['Italic' ]))print (f"📄 PDF文件生成完成: {abs_path} " )return f"PDF文件已成功生成: {abs_path} " except Exception as e:f"PDF生成失败: {str (e)} " print (error_msg)return error_msg
然后我们可以自定义不同的链路,比如简单的串行链由Playwright Agent和 generate_pdf Agent组成,即先爬取网页的内容,然后将网页中的内容写入到本地的PDF文件中。
1 2
除此以外,我们还可以再定一个摘要工具,在使用Playwright工具访问网页后,根据爬取到的网页内容先使用大模型进行摘要总结,再调用generate_pdf工具将总结内容写入到本地的PDF文件中。代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 optimization_prompt = ChatPromptTemplate.from_template("""请优化以下网站总结内容,使其更适合PDF报告格式: 原始总结: {summary} 请重新组织内容,包括: 1. 清晰的标题和结构 2. 要点总结 3. 详细说明 4. 使用要求等 优化后的内容:""" "deepseek-chat" , model_provider="deepseek" )lambda summary: {"summary" : summary})
完整的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 from langchain_community.agent_toolkits import PlayWrightBrowserToolkitfrom langchain_community.tools.playwright.utils import create_sync_playwright_browserfrom langchain import hubfrom langchain.agents import AgentExecutor, create_openai_tools_agentfrom langchain.chat_models import init_chat_modelfrom langchain_core.tools import toolfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom reportlab.lib.pagesizes import letter, A4from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacerfrom reportlab.lib.styles import getSampleStyleSheet, ParagraphStylefrom reportlab.lib.enums import TA_JUSTIFY, TA_CENTERfrom reportlab.pdfbase import pdfmetricsfrom reportlab.pdfbase.ttfonts import TTFontimport osfrom datetime import datetimeimport osfrom dotenv import load_dotenvTrue )"DEEPSEEK_API_KEY" )@tool def summarize_website (url: str ) -> str :"""访问指定网站并返回内容总结""" try :"deepseek-chat" , model_provider="deepseek" )"hwchase17/openai-tools-agent" )False )"input" : f"访问这个网站 {url} 并帮我详细总结一下这个网站的内容,包括主要功能、特点和使用方法" return result.get("output" , "无法获取网站内容总结" )except Exception as e:return f"网站访问失败: {str (e)} " @tool def generate_pdf (content: str ) -> str :"""将文本内容生成为PDF文件""" try :"%Y%m%d_%H%M%S" )f"website_summary_{timestamp} .pdf" try :"C:/Windows/Fonts/simhei.ttf" , "C:/Windows/Fonts/simsun.ttc" , "C:/Windows/Fonts/msyh.ttc" , False for font_path in font_paths:if os.path.exists(font_path):try :'ChineseFont' , font_path))True print (f"✅ 成功注册中文字体: {font_path} " )break except :continue if not chinese_font_registered:print ("⚠️ 未找到中文字体,使用默认字体" )except Exception as e:print (f"⚠️ 字体注册失败: {e} " )'CustomTitle' ,'Heading1' ],18 ,30 ,'ChineseFont' if 'chinese_font_registered' in locals () and chinese_font_registered else 'Helvetica-Bold' 'CustomContent' ,'Normal' ],11 ,20 ,20 ,12 ,'ChineseFont' if 'chinese_font_registered' in locals () and chinese_font_registered else 'Helvetica' "网站内容总结报告" , title_style))1 , 20 ))f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} " 'Normal' ]))1 , 20 ))"=" * 50 , styles['Normal' ]))1 , 15 ))if content:'\r\n' , '\n' ).replace('\r' , '\n' )'\n' )for para in paragraphs:if para.strip():'<' , '<' ).replace('>' , '>' ).replace('&' , '&' )try :1 , 8 ))except Exception as para_error:try :'Fallback' ,'Normal' ],10 ,20 ,20 ,10 1 , 8 ))except :print (f"⚠️ 段落处理失败: {clean_para[:50 ]} ..." )continue else :"暂无内容" , content_style))1 , 30 ))"=" * 50 , styles['Normal' ]))"本报告由 Playwright PDF Agent 自动生成" , styles['Italic' ]))print (f"📄 PDF文件生成完成: {abs_path} " )return f"PDF文件已成功生成: {abs_path} " except Exception as e:f"PDF生成失败: {str (e)} " print (error_msg)return error_msgprint ("=== 创建串行链:网站总结 → PDF生成 ===" )"""请优化以下网站总结内容,使其更适合PDF报告格式: 原始总结: {summary} 请重新组织内容,包括: 1. 清晰的标题和结构 2. 要点总结 3. 详细说明 4. 使用要求等 优化后的内容:""" "deepseek-chat" , model_provider="deepseek" )lambda summary: {"summary" : summary})def test_simple_chain (url: str ):"""测试简单串行链""" print (f"\n🔄 开始处理URL: {url} " )print ("📝 步骤1: 网站总结..." )print ("📄 步骤2: 生成PDF..." )print (f"✅ 完成: {result} " )return resultdef test_optimized_chain (url: str ):"""测试优化串行链""" print (f"\n🔄 开始处理URL (优化版): {url} " )print ("📝 步骤1: 网站总结..." )print ("🎨 步骤2: 内容优化..." )print ("📄 步骤3: 生成PDF..." )print (f"✅ 完成: {result} " )return resultdef create_website_pdf_report (url: str , use_optimization: bool = True ):"""创建网站PDF报告的主函数""" print ("=" * 60 )print ("🤖 网站内容PDF生成器" )print ("=" * 60 )try :if use_optimization:else :print ("\n" + "=" * 60 )print ("🎉 任务完成!" )print ("=" * 60 )return resultexcept Exception as e:f"❌ 处理失败: {str (e)} " print (error_msg)return error_msgif __name__ == "__main__" :"https://blogroll.naosi.org/" print ("选择处理方式:" )print ("1. 简单串行链(直接总结 → PDF)" )print ("2. 优化串行链(总结 → 优化 → PDF)" )input ("请选择 (1/2): " ).strip()if choice == "1" :False )elif choice == "2" :True )else :print ("使用默认优化模式..." )True )
这里仅做演示参考,实际生成效果不佳,如需使用后续还需要更精细的调整
六、LangChain 接入 MCP 技术实现流程 MCP,全称是Model Context Protocol,模型上下文协议,由Claude母公司Anthropic于去年11月正式提出。
Anthropic MCP发布通告
MCP GitHub主页
MCP的核心作用,是统一了Agent开发过程中,大模型调用外部工具的技术实现流程,从而大幅提高Agent开发效率。在MCP诞生之前,不同的外部工具各有不同的调用方法,要连接这些外部工具开发Agent,就必须“每一把锁单独配一把钥匙”,开发工作非常繁琐。
而MCP的诞生,则统一了这些外部工具的调用流程,使得无论什么样的工具,都可以借助MCP技术按照统一的一个流程快速接入到大模型中,从而大幅加快Agent开发效率。这就好比现在很多设备都可以使用type-c和电脑连接类似。
从技术实现角度来看,我们可以将MCP看成是Function calling的一种封装,通过server-client架构和一整套开发工具,来规范化Function calling开发流程。
首先来介绍一下MCP基础实现流程
langchain-mcp-adapters 项目主要为LangChain和LangGraph提供MCP的接入和兼容接口,其工作流程主要如下图所示:
实际上load_mcp_tools() 返回的是标准的 LangChain 工具,所以是完全可以直接在LangChain环境中进行使用的。同时,完全支持stdio、Http SSE和Streamable HTTP三种不同的通讯协议。
一个极简的天气查询MCP调用流程如下:
接下来,我们先尝试手动实现一遍MCP实践流程,然后再考虑将已经部署好的server代入其中,作为tools进行调用。
首先借助uv创建MCP运行环境
方法 1:使用 pip 安装(适用于已安装 pip 的系统)
方法 2:使用 curl 直接安装
如果你的系统没有 pip,可以直接运行:
1 curl -LsSf https://astral.sh/uv/install.sh | sh
这会自动下载 uv 并安装到 /usr/local/bin。
接着创建 MCP 客户端项目
1 2 3 4 5 cd mcp-client
接着创建MCP客户端虚拟环境
1 2 3 4 5 6 7 8 9 source .venv/bin/activate
然后即可通过add方法在虚拟环境中安装相关的库。
1 2
接着编写用于天气查询的server服务器代码:
这里我们需要在服务器上创建一个weather_server.py,并写入如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 import jsonimport httpxfrom typing import Any from mcp.server.fastmcp import FastMCP"WeatherServer" )"https://api.openweathermap.org/data/2.5/weather" "YOUR_API_KEY" "weather-app/1.0" async def fetch_weather (city: str ) -> dict [str , Any ] | None :""" 从 OpenWeather API 获取天气信息。 :param city: 城市名称(需使用英文,如 Beijing) :return: 天气数据字典;若出错返回包含 error 信息的字典 """ "q" : city,"appid" : API_KEY,"units" : "metric" ,"lang" : "zh_cn" "User-Agent" : USER_AGENT}async with httpx.AsyncClient() as client:try :await client.get(OPENWEATHER_API_BASE, params=params, headers=headers, timeout=30.0 )return response.json() except httpx.HTTPStatusError as e:return {"error" : f"HTTP 错误: {e.response.status_code} " }except Exception as e:return {"error" : f"请求失败: {str (e)} " }def format_weather (data: dict [str , Any ] | str ) -> str :""" 将天气数据格式化为易读文本。 :param data: 天气数据(可以是字典或 JSON 字符串) :return: 格式化后的天气信息字符串 """ if isinstance (data, str ):try :except Exception as e:return f"无法解析天气数据: {e} " if "error" in data:return f"⚠️ {data['error' ]} " "name" , "未知" )"sys" , {}).get("country" , "未知" )"main" , {}).get("temp" , "N/A" )"main" , {}).get("humidity" , "N/A" )"wind" , {}).get("speed" , "N/A" )"weather" , [{}])0 ].get("description" , "未知" )return (f"🌍 {city} , {country} \n" f"🌡 温度: {temp} °C\n" f"💧 湿度: {humidity} %\n" f"🌬 风速: {wind_speed} m/s\n" f"🌤 天气: {description} \n" @mcp.tool() async def query_weather (city: str ) -> str :""" 输入指定城市的英文名称,返回今日天气查询结果。 :param city: 城市名称(需使用英文) :return: 格式化后的天气信息 """ await fetch_weather(city)return format_weather(data)if __name__ == "__main__" :'stdio' )
为了更好的测试多MCP工具调用流程,这里我们继续创建一个write_server.py服务器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import jsonimport httpxfrom typing import Any from mcp.server.fastmcp import FastMCP"WriteServer" )"write-app/1.0" @mcp.tool() async def write_file (content: str ) -> str :""" 将指定内容写入本地文件。 :param content: 必要参数,字符串类型,用于表示需要写入文档的具体内容。 :return:是否成功写入 """ return "已成功写入本地文件。" if __name__ == "__main__" :'stdio' )
然后创建一个可以和server进行通信的客户端
需要注意的是,该客户端需要包含大模型调用的基础信息。我们需要编写一个client.py脚本,这个脚本内容非常复杂,这里提供的是通用的mcp客户端脚本,还未接入Langchain,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 import asyncioimport jsonimport loggingimport osimport shutilfrom contextlib import AsyncExitStackfrom typing import Any , Dict , List , Optional import httpxfrom dotenv import load_dotenvfrom openai import OpenAI from mcp import ClientSession, StdioServerParametersfrom mcp.client.stdio import stdio_clientformat ="%(asctime)s - %(levelname)s - %(message)s" class Configuration :"""管理 MCP 客户端的环境变量和配置文件""" def __init__ (self ) -> None :self .api_key = os.getenv("LLM_API_KEY" )self .base_url = os.getenv("BASE_URL" )self .model = os.getenv("MODEL" )if not self .api_key:raise ValueError("❌ 未找到 LLM_API_KEY,请在 .env 文件中配置" ) @staticmethod def load_config (file_path: str ) -> Dict [str , Any ]:""" 从 JSON 文件加载服务器配置 Args: file_path: JSON 配置文件路径 Returns: 包含服务器配置的字典 """ with open (file_path, "r" ) as f:return json.load(f)class Server :"""管理单个 MCP 服务器连接和工具调用""" def __init__ (self, name: str , config: Dict [str , Any ] ) -> None :self .name: str = nameself .config: Dict [str , Any ] = configself .session: Optional [ClientSession] = None self .exit_stack: AsyncExitStack = AsyncExitStack()self ._cleanup_lock = asyncio.Lock()async def initialize (self ) -> None :"""初始化与 MCP 服务器的连接""" self .config["command" ]if command is None :raise ValueError("command 不能为空" )self .config["args" ],self .config["env" ]} if self .config.get("env" ) else None ,try :await self .exit_stack.enter_async_context(await self .exit_stack.enter_async_context(await session.initialize()self .session = sessionexcept Exception as e:f"Error initializing server {self.name} : {e} " )await self .cleanup()raise async def list_tools (self ) -> List [Any ]:"""获取服务器可用的工具列表 Returns: 工具列表 """ if not self .session:raise RuntimeError(f"Server {self.name} not initialized" )await self .session.list_tools()for item in tools_response:if isinstance (item, tuple ) and item[0 ] == "tools" :for tool in item[1 ]:return toolsasync def execute_tool ( self, tool_name: str , arguments: Dict [str , Any ], retries: int = 2 , delay: float = 1.0 ) -> Any :"""执行指定工具,并支持重试机制 Args: tool_name: 工具名称 arguments: 工具参数 retries: 重试次数 delay: 重试间隔秒数 Returns: 工具调用结果 """ if not self .session:raise RuntimeError(f"Server {self.name} not initialized" )0 while attempt < retries:try :f"Executing {tool_name} on server {self.name} ..." )await self .session.call_tool(tool_name, arguments)return resultexcept Exception as e:1 f"Error executing tool: {e} . Attempt {attempt} of {retries} ." if attempt < retries:f"Retrying in {delay} seconds..." )await asyncio.sleep(delay)else :"Max retries reached. Failing." )raise async def cleanup (self ) -> None :"""清理服务器资源""" async with self ._cleanup_lock:try :await self .exit_stack.aclose()self .session = None except Exception as e:f"Error during cleanup of server {self.name} : {e} " )class Tool :"""封装 MCP 返回的工具信息""" def __init__ (self, name: str , description: str , input_schema: Dict [str , Any ] ) -> None :self .name: str = nameself .description: str = descriptionself .input_schema: Dict [str , Any ] = input_schemadef format_for_llm (self ) -> str :"""生成用于 LLM 提示的工具描述""" if "properties" in self .input_schema:for param_name, param_info in self .input_schema["properties" ].items():f"- {param_name} : {param_info.get('description' , 'No description' )} " if param_name in self .input_schema.get("required" , []):" (required)" return f""" Tool: {self.name} Description: {self.description} Arguments: {chr (10 ).join(args_desc)} """ class LLMClient :"""使用 OpenAI SDK 与大模型交互""" def __init__ (self, api_key: str , base_url: Optional [str ], model: str ) -> None :self .client = OpenAI(api_key=api_key, base_url=base_url)self .model = modeldef get_response (self, messages: List [Dict [str , Any ]], tools: Optional [List [Dict [str , Any ]]] = None ) -> Any :""" 发送消息给大模型 API,支持传入工具参数(function calling 格式) """ "model" : self .model,"messages" : messages,"tools" : tools,try :self .client.chat.completions.create(**payload)return responseexcept Exception as e:f"Error during LLM call: {e} " )raise class MultiServerMCPClient :def __init__ (self ) -> None :""" 管理多个 MCP 服务器,并使用 OpenAI Function Calling 风格的接口调用大模型 """ self .exit_stack = AsyncExitStack()self .openai_api_key = config.api_keyself .base_url = config.base_urlself .model = config.modelself .client = LLMClient(self .openai_api_key, self .base_url, self .model)self .servers: Dict [str , Server] = {}self .tools_by_server: Dict [str , List [Any ]] = {}self .all_tools: List [Dict [str , Any ]] = []async def connect_to_servers (self, servers_config: Dict [str , Any ] ) -> None :""" 根据配置文件同时启动多个服务器并获取工具 servers_config 的格式为: { "mcpServers": { "sqlite": { "command": "uvx", "args": [ ... ] }, "puppeteer": { "command": "npx", "args": [ ... ] }, ... } } """ "mcpServers" , {})for server_name, srv_config in mcp_servers.items():await server.initialize()self .servers[server_name] = serverawait server.list_tools()self .tools_by_server[server_name] = toolsfor tool in tools:f"{server_name} _{tool.name} " self .all_tools.append({"type" : "function" ,"function" : {"name" : function_name,"description" : tool.description,"input_schema" : tool.input_schemaself .all_tools = await self .transform_json(self .all_tools)"\n✅ 已连接到下列服务器:" )for name in self .servers:f" - {name} : command={srv_cfg['command' ]} , args={srv_cfg['args' ]} " )"\n汇总的工具:" )for t in self .all_tools:f" - {t['function' ]['name' ]} " )async def transform_json (self, json_data: List [Dict [str , Any ]] ) -> List [Dict [str , Any ]]:""" 将工具的 input_schema 转换为 OpenAI 所需的 parameters 格式,并删除多余字段 """ for item in json_data:if not isinstance (item, dict ) or "type" not in item or "function" not in item:continue "function" ]if not isinstance (old_func, dict ) or "name" not in old_func or "description" not in old_func:continue "name" : old_func["name" ],"description" : old_func["description" ],"parameters" : {}if "input_schema" in old_func and isinstance (old_func["input_schema" ], dict ):"input_schema" ]"parameters" ]["type" ] = old_schema.get("type" , "object" )"parameters" ]["properties" ] = old_schema.get("properties" , {})"parameters" ]["required" ] = old_schema.get("required" , [])"type" : item["type" ],"function" : new_funcreturn resultasync def chat_base (self, messages: List [Dict [str , Any ]] ) -> Any :""" 使用 OpenAI 接口进行对话,并支持多次工具调用(Function Calling)。 如果返回 finish_reason 为 "tool_calls",则进行工具调用后再发起请求。 """ self .client.get_response(messages, tools=self .all_tools)if response.choices[0 ].finish_reason == "tool_calls" :while True :await self .create_function_response_messages(messages, response)self .client.get_response(messages, tools=self .all_tools)if response.choices[0 ].finish_reason != "tool_calls" :break return responseasync def create_function_response_messages (self, messages: List [Dict [str , Any ]], response: Any ) -> List [Dict [str , Any ]]:""" 将模型返回的工具调用解析执行,并将结果追加到消息队列中 """ 0 ].message.tool_calls0 ].message.model_dump())for function_call_message in function_call_messages:await self ._call_mcp_tool(tool_name, tool_args)"role" : "tool" ,"content" : function_response,"tool_call_id" : function_call_message.id ,return messagesasync def process_query (self, user_query: str ) -> str :""" OpenAI Function Calling 流程: 1. 发送用户消息 + 工具信息 2. 若模型返回 finish_reason 为 "tool_calls",则解析并调用 MCP 工具 3. 将工具调用结果返回给模型,获得最终回答 """ "role" : "user" , "content" : user_query}]self .client.get_response(messages, tools=self .all_tools)0 ]if content.finish_reason == "tool_calls" :0 ]f"\n[ 调用工具: {tool_name} , 参数: {tool_args} ]\n" )await self ._call_mcp_tool(tool_name, tool_args)"role" : "tool" ,"content" : result,"tool_call_id" : tool_call.id ,self .client.get_response(messages, tools=self .all_tools)return response.choices[0 ].message.contentreturn content.message.contentasync def _call_mcp_tool (self, tool_full_name: str , tool_args: Dict [str , Any ] ) -> str :""" 根据 "serverName_toolName" 格式调用相应 MCP 工具 """ "_" , 1 )if len (parts) != 2 :return f"无效的工具名称: {tool_full_name} " self .servers.get(server_name)if not server:return f"找不到服务器: {server_name} " await server.execute_tool(tool_name, tool_args)if isinstance (content, list ):for c in content if hasattr (c, "text" )]return "\n" .join(texts)elif isinstance (content, dict ) or isinstance (content, list ):return json.dumps(content, ensure_ascii=False )elif content is None :return "工具执行无输出" else :return str (content)async def chat_loop (self ) -> None :"""多服务器 MCP + OpenAI Function Calling 客户端主循环""" "\n🤖 多服务器 MCP + Function Calling 客户端已启动!输入 'quit' 退出。" )List [Dict [str , Any ]] = []while True :input ("\n你: " ).strip()if query.lower() == "quit" :break try :"role" : "user" , "content" : query})20 :] await self .chat_base(messages)0 ].message.model_dump())0 ].message.contentprint (f"\nAI: {result} " )except Exception as e:print (f"\n⚠️ 调用过程出错: {e} " )async def cleanup (self ) -> None :"""关闭所有资源""" await self .exit_stack.aclose()async def main () -> None :"servers_config.json" )try :await client.connect_to_servers(servers_config)await client.chat_loop()finally :try :await asyncio.sleep(0.1 )await client.cleanup()except RuntimeError as e:if "Attempted to exit cancel scope" in str (e):"退出时检测到 cancel scope 异常,已忽略。" )else :raise if __name__ == "__main__" :
接下来继续创建一个.env文件,来保存大模型调用的API-KEY
并写入如下内容:
1 2 3 BASE_URL=https://api.deepseek.com
接下来继续创建servers_config.json文件,用于保存MCP工具基本信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "mcpServers" : { "weather" : { "command" : "python" , "args" : [ "weather_server.py" ] , "transport" : "stdio" } , "write" : { "command" : "python" , "args" : [ "write_server.py" ] , "transport" : "stdio" } } }
最后在命令行中执行如下命令,注意在此之前要先启动两个mcp服务器脚本,即可开启对话:
至此,即完成了一次简单的MCP执行流程。
上面是使用Function calling直接调用MCP的工具
接下来来介绍**MCP+LangChain的基础调用流程**,代码量也会大幅减少
LangChain调用MCP是可以将MCP的工具直接转换为LangChain的工具,然后通过预定义的MCP_Client实现与外部MCP的读写操作,换而言之就是我们需要改写原先的client,将原先的Function calling调用逻辑修改为LangChain调用逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 """ 多服务器 MCP + LangChain Agent 示例 --------------------------------- 1. 读取 .env 中的 LLM_API_KEY / BASE_URL / MODEL 2. 读取 servers_config.json 中的 MCP 服务器信息 3. 启动 MCP 服务器(支持多个) 4. 将所有工具注入 LangChain Agent,由大模型自动选择并调用 """ import asyncioimport jsonimport loggingimport osfrom typing import Any , Dict , List from dotenv import load_dotenvfrom langchain import hubfrom langchain.agents import AgentExecutor, create_openai_tools_agentfrom langchain.chat_models import init_chat_modelfrom langchain_mcp_adapters.client import MultiServerMCPClientfrom langchain_mcp_adapters.tools import load_mcp_toolsclass Configuration :"""读取 .env 与 servers_config.json""" def __init__ (self ) -> None :self .api_key: str = os.getenv("LLM_API_KEY" ) or "" self .base_url: str | None = os.getenv("BASE_URL" ) self .model: str = os.getenv("MODEL" ) or "deepseek-chat" if not self .api_key:raise ValueError("❌ 未找到 LLM_API_KEY,请在 .env 中配置" ) @staticmethod def load_servers (file_path: str = "servers_config.json" ) -> Dict [str , Any ]:with open (file_path, "r" , encoding="utf-8" ) as f:return json.load(f).get("mcpServers" , {})async def run_chat_loop () -> None :"""启动 MCP-Agent 聊天循环""" "DEEPSEEK_API_KEY" ] = os.getenv("LLM_API_KEY" , "" )if cfg.base_url:"DEEPSEEK_API_BASE" ] = cfg.base_url"OPENAI_API_KEY" ] = cfg.api_keyif cfg.base_url: "OPENAI_BASE_URL" ] = cfg.base_urlawait mcp_client.get_tools() f"✅ 已加载 {len (tools)} 个 MCP 工具: {[t.name for t in tools]} " )"deepseek" if "deepseek" in cfg.model else "openai" ,"hwchase17/openai-tools-agent" )True )print ("\n🤖 MCP Agent 已启动,输入 'quit' 退出" )while True :input ("\n你: " ).strip()if user_input.lower() == "quit" :break try :await agent_executor.ainvoke({"input" : user_input})print (f"\nAI: {result['output' ]} " )except Exception as exc:print (f"\n⚠️ 出错: {exc} " )await mcp_client.cleanup()print ("🧹 资源已清理,Bye!" )if __name__ == "__main__" :format ="%(asctime)s - %(levelname)s - %(message)s" )
LangChain接入MCP的核心原理为: weather_server.py → 启动为子进程 → stdio 通信 → MCP 协议 → 转换为 LangChain 工具 → LangChain Agent 执行读写,核心转换过程为:
@mcp.tool() → 标准 LangChain Tool
stdio_client() → 自动处理 read/write 流,其中read 表示从 MCP 服务器读取响应的流,write 表示向 MCP 服务器发送请求的流,对于 stdio weather_server.py,它们就是子进程的 stdout 和 stdin
load_mcp_tools() → 一键转换所有工具
七、LangChain RAG知识库检索系统开发 首先介绍LangChain 实现本地知识库问答
供Agents在处理复杂任务的某个阶段使用,这其实是一种更为复杂的应用架构——Agent + RAG。
假设现在我们有一个偌大的知识库,当想从该知识库中去检索最相关的内容时,最简单的方法是:接收到一个查询(Query),就直接在知识库中进行搜索。这种做法其实是可行的,但存在两个关键的问题:
假设提问的Query的答案出现在一篇文章中,去知识库中找到一篇与用户输入相关的文章是很容易的,但是我们将检索到的这整篇文章直接放入Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。
任何一个大模型都存在最大输入的Token限制,一个流程中可能涉及多次检索,每次检索都会产生相应的上下文,无法容纳如此多的信息。
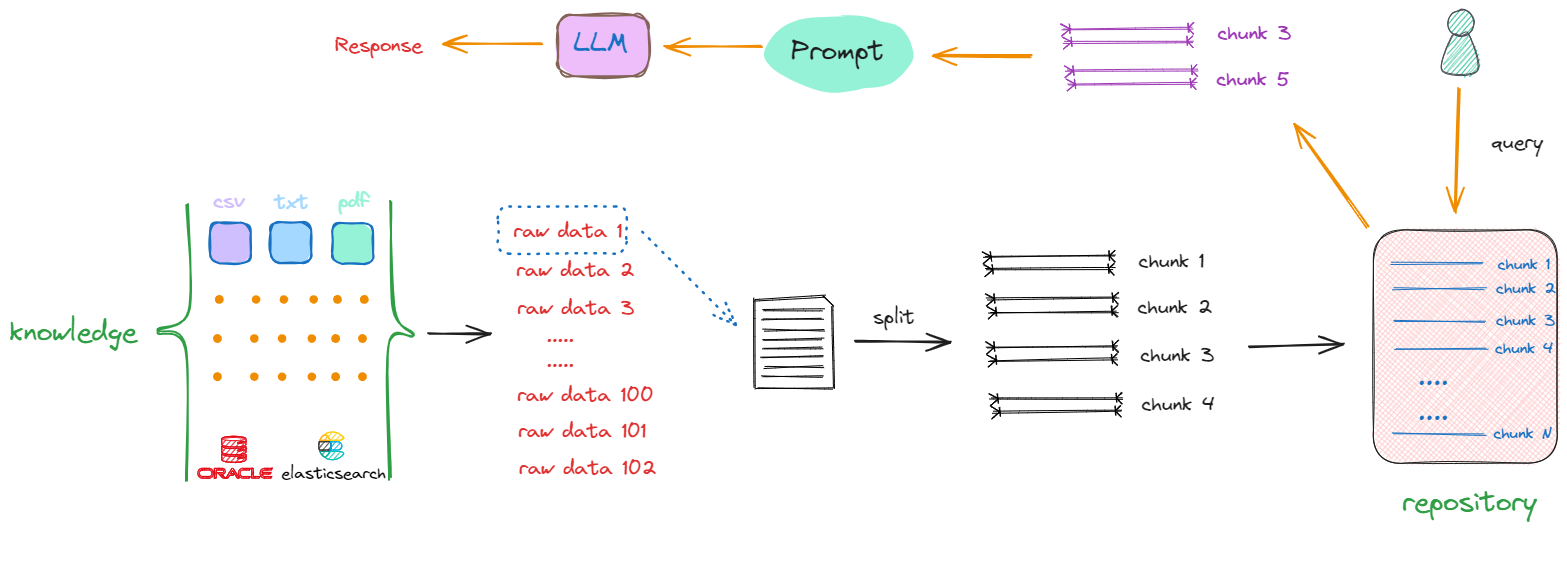
解决上述两个问题的方式是:把存放着原始数据的知识库(Knowledge)中的每一个raw data,切分成一个一个的小块,这些小块可以是一个段落,也可以是数据库中某个索引对应的值。这个切分过程被称为“分块”(chunking),如下述流程所示:
以第一个原始数据为例(raw data 1),通过一些特定的方法进行切分,一个完整的内容会被分割成 chunk1 ~ chunk4。采取相同的方法,继续对raw data 2、raw data 3直至raw data n进行切分。完成这一过程后,我们最终得到的是一个充满分块数据(chunks)的新的知识库(repository),其中每一项都是一个单独的chunk。例如,如果原始文档共有10个,那么经过切分,可能会产生出100个chunks。
完成这一转化后,当再次接收到一个查询(Query)时,就会在更新后的知识库(repository)中进行搜索,这时检索的范围就不再是某个完整的文档,而是其中的某一个部分,返回的是一个或多个特定的chunk,这样返回的信息量就会更小且更精确。随后,这些被检索到的chunk会被加入到Prompt中,作为上下文信息与用户原始的Query共同输入到大模型进行处理,以生成最终的回答。
在上述将原始数据(raw data)转化为chunk的过程中,就会包含构建RAG的第一部分开发工作:这包括如果做数据清洗,如去除停用词、标点符号等。此外,还涉及如何选择合适的split方法来进行数据切分的一系列技术。
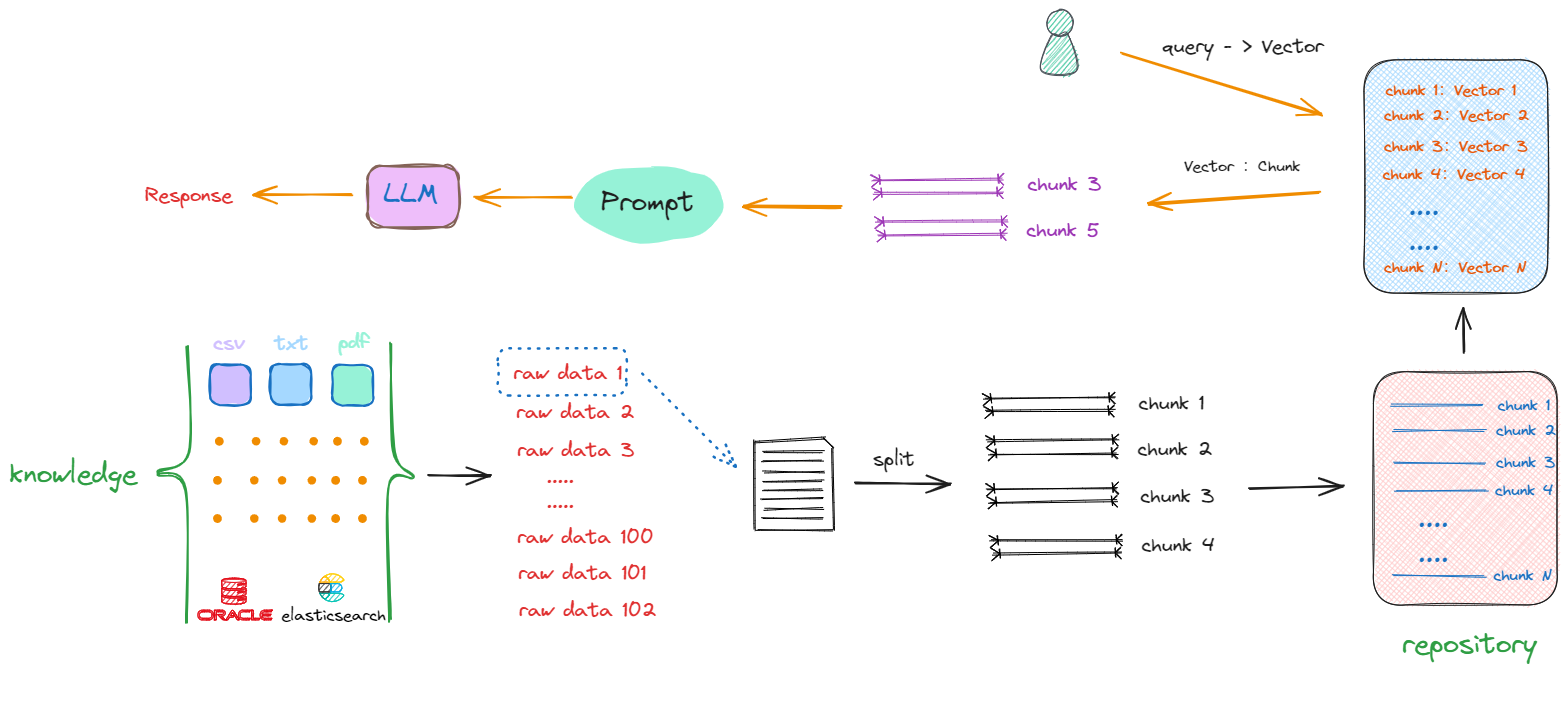
接下来面临的问题是,尽管所有数据已经被切割成一个个chunk,其存储形式还是以字符串形式存在,如果想从repository中匹配到与输入的query相关的chunks,比较两句话是否相似,看一句话中相同字有几个,这显然是行不通的。我们需要获取的是句子所蕴含的深层含义,而非仅仅是表面的字面相似度。因此,大家也能想到,在NLP中去计算文本相似度的有效的方法就是Embedding,即将这些chunks转换成向量(vector)形式。所以流程会丰富如下:
如上所示,解决搜索效率和计算相似度优化算法的答案就是:向量数据库。同时也产生了构建RAG的第三部分工作:我们要去了解和学习如何选择、使用向量数据库。
最终整体流程就如上图所示,一个基础的RAG架构会只要包含以下几方面的开发工作:
如何将原始数据转化成chunks;
如何将chunks转化成Vector;
如何算向量相似度的算法;
如何利用向量数据库提升搜索效率;
如何把找到的chunks与原始query拼接在一起,产生最终的Prompt;
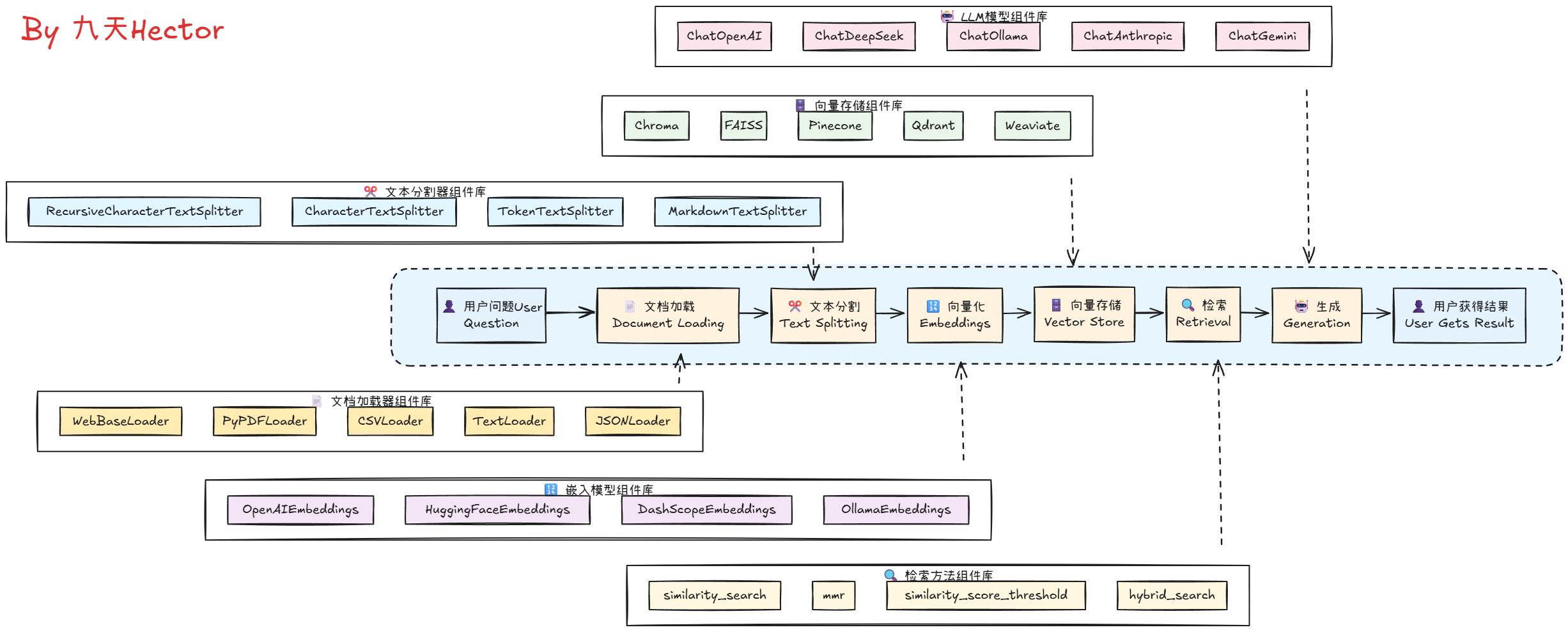
而上述流程,其实更像是一个自由拼接的结果,比如不同的文档类型可以选择不同的文档解析器,也可以选择不同的Vector数据库,甚至可以自由选择Embedding模型和Vector数据库的组合。其自由程度非常高,如下图所示:
由于这一部分比较复杂,因此在这仅给出示例代码,后续再做补充(后面的内容有需要可以看,也可以等后续给出更详细的教程) 下面是通过 Streamlit 前端界面,结合 LangChain 框架 与 DashScope 向量嵌入服务,实现了一个轻量化的 RAG(Retrieval-Augmented Generation) 智能问答系统,支持上传多个 PDF 文档,系统将自动完成文本提取、分块、向量化,并构建基于 FAISS 的检索数据库。用户随后可以在页面中输入任意问题,系统会调用大语言模型(如 DeepSeek-Chat)对 PDF 内容进行语义理解和回答生成。
其完整代码如下所示:
1 ! pip install streamlit PyPDF2 dashscope faiss-cpu
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 import streamlit as stfrom PyPDF2 import PdfReaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_community.vectorstores import FAISSfrom langchain.tools.retriever import create_retriever_toolfrom langchain.agents import AgentExecutor, create_tool_calling_agentfrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain.chat_models import init_chat_modelimport osfrom dotenv import load_dotenvTrue )"DEEPSEEK_API_KEY" )"dashscope_api_key" )"KMP_DUPLICATE_LIB_OK" ] = "TRUE" "text-embedding-v1" , dashscope_api_key=dashscope_api_keydef pdf_read (pdf_doc ):"" for pdf in pdf_doc:for page in pdf_reader.pages:return textdef get_chunks (text ):1000 , chunk_overlap=200 )return chunksdef vector_store (text_chunks ):"faiss_db" )def get_conversational_chain (tools, ques ):"deepseek-chat" , model_provider="deepseek" )"system" ,"""你是AI助手,请根据提供的上下文回答问题,确保提供所有细节,如果答案不在上下文中,请说"答案不在上下文中",不要提供错误的答案""" ,"placeholder" , "{chat_history}" ),"human" , "{input}" ),"placeholder" , "{agent_scratchpad}" ),True )"input" : ques})print (response)"🤖 回答: " , response['output' ])def check_database_exists ():"""检查FAISS数据库是否存在""" return os.path.exists("faiss_db" ) and os.path.exists("faiss_db/index.faiss" )def user_input (user_question ):if not check_database_exists():"❌ 请先上传PDF文件并点击'Submit & Process'按钮来处理文档!" )"💡 步骤:1️⃣ 上传PDF → 2️⃣ 点击处理 → 3️⃣ 开始提问" )return try :"faiss_db" , embeddings, allow_dangerous_deserialization=True )"pdf_extractor" ,"This tool is to give answer to queries from the pdf" )except Exception as e:f"❌ 加载数据库时出错: {str (e)} " )"请重新处理PDF文件" )def main ():"🤖 LangChain B站公开课 By九天Hector" )"🤖 LangChain B站公开课 By九天Hector" )3 , 1 ])with col1:if check_database_exists():pass else :"⚠️ 请先上传并处理PDF文件" )with col2:if st.button("🗑️ 清除数据库" ):try :import shutilif os.path.exists("faiss_db" ):"faiss_db" )"数据库已清除" )except Exception as e:f"清除失败: {e} " )"💬 请输入问题" ,"例如:这个文档的主要内容是什么?" ,not check_database_exists())if user_question:if check_database_exists():with st.spinner("🤔 AI正在分析文档..." ):else :"❌ 请先上传并处理PDF文件!" )with st.sidebar:"📁 文档管理" )if check_database_exists():"✅ 数据库状态:已就绪" )else :"📝 状态:等待上传PDF" )"---" )"📎 上传PDF文件" ,True ,type =['pdf' ],help ="支持上传多个PDF文件" if pdf_doc:f"📄 已选择 {len (pdf_doc)} 个文件" )for i, pdf in enumerate (pdf_doc, 1 ):f"{i} . {pdf.name} " )"🚀 提交并处理" ,not pdf_doc,True if process_button:if pdf_doc:with st.spinner("📊 正在处理PDF文件..." ):try :if not raw_text.strip():"❌ 无法从PDF中提取文本,请检查文件是否有效" )return f"📝 文本已分割为 {len (text_chunks)} 个片段" )"✅ PDF处理完成!现在可以开始提问了" )except Exception as e:f"❌ 处理PDF时出错: {str (e)} " )else :"⚠️ 请先选择PDF文件" )with st.expander("💡 使用说明" ):""" **步骤:** 1. 📎 上传一个或多个PDF文件 2. 🚀 点击"Submit & Process"处理文档 3. 💬 在主页面输入您的问题 4. 🤖 AI将基于PDF内容回答问题 **提示:** - 支持多个PDF文件同时上传 - 处理大文件可能需要一些时间 - 可以随时清除数据库重新开始 """ )if __name__ == "__main__" :
基于此,我们能够实现:
LangChain 的多模块能力 (向量搜索 + Agent工具)Streamlit 前端交互 FAISS 向量数据库 DashScope Embedding + DeepSeek 模型接入 并完成了完整的 RAG(检索增强生成)流程
以下是各部分功能实现代码讲解:
🔧 1. 导入库 & 环境初始化
1 2 3 4 5 import streamlit as stfrom PyPDF2 import PdfReaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterTrue )
🔐 2. 加载 API 密钥与设置环境变量
1 2 3 DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY" )"dashscope_api_key" )"KMP_DUPLICATE_LIB_OK" ]="TRUE"
从环境变量中读取 DashScope 和 DeepSeek API。
设置 KMP_DUPLICATE_LIB_OK 避免某些 MKL 多线程报错。
🧠 3. 初始化向量 Embedding 模型
1 2 3 embeddings = DashScopeEmbeddings("text-embedding-v1" , dashscope_api_key=dashscope_api_key
用阿里云 DashScope 提供的 text-embedding-v1 将文本转为向量表示,用于相似度搜索。
📄 4. 处理 PDF 文本与向量化逻辑
1 2 3 4 5 6 def pdf_read (pdf_doc ):def get_chunks (text ):def vector_store (text_chunks ):
pdf_read:逐页读取 PDF 内容并拼接。get_chunks:将长文本切片为多个段落(chunk),每段 1000 字,重叠 200 字。vector_store:用 FAISS 建立向量索引,并保存到本地 faiss_db/。
🔁 5. Agent对话链 + 工具调用(核心 RAG)
1 2 3 4 5 6 def get_conversational_chain (tools, ques ):"deepseek-chat" , model_provider="deepseek" )"input" : ques})
🔍 6. 用户提问逻辑(调用 FAISS)
1 2 3 4 5 6 def user_input (user_question ):"faiss_db" , embeddings, ...)"pdf_extractor" , ...)
加载本地 FAISS 向量库;
将其转为 LangChain 的检索工具;
交由 Agent 调用完成回答。
🧠 7. 检查数据库是否存在
1 2 def check_database_exists ():return os.path.exists("faiss_db" ) and os.path.exists("faiss_db/index.faiss" )
简单检查本地是否已有向量化数据。
🌐 8. 主界面逻辑(Streamlit)
1 2 3 def main ():
🎯 9. 提交 PDF 后执行的逻辑
1 2 3 4 5 if process_button:
当点击“提交并处理”后:
读取上传的 PDF;
切片文本;
向量化入库;
弹出气球提示,并 st.rerun() 刷新页面状态。
📎 项目结构总结
模块
说明
🧾 PDF解析
读取用户上传的 PDF
✂️ 文本切片
按段落分割内容
📊 向量化
DashScope Embedding + FAISS 建库
🔁 查询接口
用户输入 → 召回相关 chunk
🤖 DeepSeek Agent
调用检索工具并给出回答
💻 UI层
Streamlit 实现全部交互
其中LangChain RAG核心功能相关代码如下:
Step 1:PDF 文件上传与文本提取
使用 st.file_uploader() 组件支持多文件上传,并通过 PyPDF2.PdfReader 对每页内容进行提取,组合为整体文本。
1 2 3 4 5 6 7 def pdf_read (pdf_doc ):"" for pdf in pdf_doc:for page in pdf_reader.pages:return text
Step 2:文本分块与向量数据库构建
使用 RecursiveCharacterTextSplitter 将长文档切割为固定长度(1000字)+ 重叠(200字)的小块,将文本块通过 DashScopeEmbeddings 嵌入为向量,使用 FAISS 本地存储向量数据库。
1 2 3 chunks = text_splitter.split_text(text)"faiss_db" )
Step 3:用户提问与语义检索
通过 Streamlit 获取用户输入问题,如果向量数据库存在,则加载 FAISS 检索器,使用 create_retriever_tool() 构建 LangChain 工具,交由 AgentExecutor 执行,自动调用检索器并生成答案。
1 2 3 retrieval_chain = create_retriever_tool(retriever, ...)"input" : ques})
下面再基于LangChain搭建AI数据分析智能体Data Agent
接下来,我们进一步丰富智能问答系统的功能,接下来的案例中,我们构建一个基于 Streamlit + LangChain + DashScope + DeepSeek 的智能化数据分析助手,融合两个典型的企业级大模型应用场景:
完整代码如下所示:
1 pip install langchain_experimental matplotlib tabulate
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 import streamlit as stimport pandas as pdimport osfrom PyPDF2 import PdfReaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_community.vectorstores import FAISSfrom langchain.tools.retriever import create_retriever_toolfrom langchain.agents import AgentExecutor, create_tool_calling_agentfrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain.chat_models import init_chat_modelfrom langchain_experimental.tools import PythonAstREPLToolimport matplotlib'Agg' )import osfrom dotenv import load_dotenvTrue )"DEEPSEEK_API_KEY" )"dashscope_api_key" )"KMP_DUPLICATE_LIB_OK" ] = "TRUE" "By九天Hector" ,"🤖" ,"wide" ,"expanded" """ <style> /* 主题色彩 */ :root { --primary-color: #1f77b4; --secondary-color: #ff7f0e; --success-color: #2ca02c; --warning-color: #ff9800; --error-color: #d62728; --background-color: #f8f9fa; } /* 隐藏默认的Streamlit样式 */ #MainMenu {visibility: hidden;} footer {visibility: hidden;} header {visibility: hidden;} /* 标题样式 */ .main-header { background: linear-gradient(90deg, #1f77b4, #ff7f0e); -webkit-background-clip: text; -webkit-text-fill-color: transparent; font-size: 3rem; font-weight: bold; text-align: center; margin-bottom: 2rem; } /* 卡片样式 */ .info-card { background: white; padding: 1.5rem; border-radius: 10px; box-shadow: 0 2px 10px rgba(0,0,0,0.1); margin: 1rem 0; border-left: 4px solid var(--primary-color); } .success-card { background: linear-gradient(135deg, #e8f5e8, #f0f8f0); border-left: 4px solid var(--success-color); } .warning-card { background: linear-gradient(135deg, #fff8e1, #fffbf0); border-left: 4px solid var(--warning-color); } /* 按钮样式 */ .stButton > button { background: linear-gradient(45deg, #1f77b4, #2196F3); color: white; border: none; border-radius: 8px; padding: 0.5rem 1rem; font-weight: 600; transition: all 0.3s ease; box-shadow: 0 2px 8px rgba(31, 119, 180, 0.3); } .stButton > button:hover { transform: translateY(-2px); box-shadow: 0 4px 12px rgba(31, 119, 180, 0.4); } /* Tab样式 */ .stTabs [data-baseweb="tab-list"] { gap: 8px; background-color: #f8f9fa; border-radius: 10px; padding: 0.5rem; } .stTabs [data-baseweb="tab"] { height: 60px; background-color: white; border-radius: 8px; padding: 0 24px; font-weight: 600; border: 2px solid transparent; transition: all 0.3s ease; } .stTabs [aria-selected="true"] { background: linear-gradient(45deg, #1f77b4, #2196F3); color: white !important; border: 2px solid #1f77b4; } /* 侧边栏样式 */ .css-1d391kg { background: linear-gradient(180deg, #f8f9fa, #ffffff); } /* 文件上传区域 */ .uploadedFile { background: #f8f9fa; border: 2px dashed #1f77b4; border-radius: 10px; padding: 1rem; text-align: center; margin: 1rem 0; } /* 状态指示器 */ .status-indicator { display: inline-flex; align-items: center; gap: 0.5rem; padding: 0.5rem 1rem; border-radius: 20px; font-weight: 600; font-size: 0.9rem; } .status-ready { background: #e8f5e8; color: #2ca02c; border: 1px solid #2ca02c; } .status-waiting { background: #fff8e1; color: #ff9800; border: 1px solid #ff9800; } </style> """ , unsafe_allow_html=True )@st.cache_resource def init_embeddings ():return DashScopeEmbeddings("text-embedding-v1" ,@st.cache_resource def init_llm ():return init_chat_model("deepseek-chat" , model_provider="deepseek" )def init_session_state ():if 'pdf_messages' not in st.session_state:if 'csv_messages' not in st.session_state:if 'df' not in st.session_state:None def pdf_read (pdf_doc ):"" for pdf in pdf_doc:for page in pdf_reader.pages:return textdef get_chunks (text ):1000 , chunk_overlap=200 )return chunksdef vector_store (text_chunks ):"faiss_db" )def check_database_exists ():return os.path.exists("faiss_db" ) and os.path.exists("faiss_db/index.faiss" )def get_pdf_response (user_question ):if not check_database_exists():return "❌ 请先上传PDF文件并点击'Submit & Process'按钮来处理文档!" try :"faiss_db" , embeddings, allow_dangerous_deserialization=True )"system" ,"""你是AI助手,请根据提供的上下文回答问题,确保提供所有细节,如果答案不在上下文中,请说"答案不在上下文中",不要提供错误的答案""" ),"placeholder" , "{chat_history}" ),"human" , "{input}" ),"placeholder" , "{agent_scratchpad}" ),"pdf_extractor" ,"This tool is to give answer to queries from the pdf" )True )"input" : user_question})return response['output' ]except Exception as e:return f"❌ 处理问题时出错: {str (e)} " def get_csv_response (query: str ) -> str :if st.session_state.df is None :return "请先上传CSV文件" 'df' : st.session_state.df}locals =locals_dict)]f"""Given a pandas dataframe `df` answer user's query. Here's the output of `df.head().to_markdown()` for your reference, you have access to full dataframe as `df`:
{st.session_state.df.head().to_markdown()}
1 2 3 Give final answer as soon as you have enough data, otherwise generate code using `df` and call required tool.
GRAPH:Age histogram 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 Query:"""
✅ 总结(核心功能架构)
模块
技术组件
说明
PDF 问答
FAISS + Retriever Tool
构成 RAG 检索增强流程
CSV 分析
PythonAstREPLTool + Pandas
实现代码生成 + 可视化
LLM
DeepSeek Chat
统一 Agent 调用
向量库
DashScope Embedding + FAISS
支持中文语义匹配
UI
Streamlit + 自定义 CSS
提供多 Tab 页面与交互式聊天
状态管理
st.session_state管理历史、数据、图片等上下文
这里不再重复赘述PDF智能问答的流程,重点说明CSV数据智能分析的流程。
Step 1. CSV 文件上传与 DataFrame 显示
用户上传 .csv 文件后由 pandas.read_csv() 加载为 DataFrame,实时预览数据行列、列名、类型等信息。
1 2 st.session_state.df = pd.read_csv(csv_file)
Step 2. 构建代码执行工具 Agent
构建系统提示,注入 DataFrame 的 .head() 输出增强语境理解,使用 PythonAstREPLTool 工具允许模型执行基于 df 的代码分析,通过 create_tool_calling_agent 构建分析 Agent,可执行筛选、分组、聚合等 pandas 操作,图表绘制(保存为 plot.png,关键词识别后渲染)。
1 tools = [PythonAstREPLTool(locals ={"df" : st.session_state.df})]
Step 3. 图表识别与自动展示
若模型返回内容中包含 “GRAPH:”,则自动读取 plot.png 并展示;支持 plt.hist()、plt.bar() 等可视化命令;会话记录中分类保存文本、图像与表格类型内容。